

Developing data models and dashboards should be a smooth process, but teams using dbt for transformation and Looker for visualisation often face challenges. This article outlines a practical strategy for achieving reliable development and efficient environment separation between dbt and Looker. We’ll explore how to use a dedicated development data warehouse, robust Looker tests integration with Spectacles, and smart branch management to avoid disruptions, ensure data quality and control spending.
Challenges with using dbt and Looker
As we develop data models using dbt, a SQL-first transformation tool, and create dashboards with Looker, a BI platform, two key challenges often arise:
- Reliable Development: How can we confidently develop in dbt without disrupting existing business Looker dashboards?
- Looker Environment Separation: How can we effectively separate development and production environments without incurring additional costs?
By implementing a dedicated development environment and robust testing, teams can avoid disruptions to production dashboards, safeguard data quality, and control costs.
Overcoming these challenges brings significant benefits:
- Fewer Errors: Ensures changes don’t impact existing production dashboards.
- Increased Confidence: Builds trust in your processes and outcomes with business users.
- Improved Data Quality: Validates changes before deploying to production.
- Faster Deployment: Accelerates development cycles without downtime.
- Cost Efficiency: Avoids extra infrastructure expenses.
In this blog post, we’ll explore practical solutions to these challenges and how they can streamline your data development workflow.

Ensuring Reliable Development
To ensure seamless development and maintain quality between dbt and Looker, there are two key prerequisites:
- A dedicated development data warehouse.
- Robust tests in Looker
Setting Up a Dedicated development data warehouse
A development data warehouse is a separate environment from production, specifically set up for testing and building new features. Unlike production, it provides a safe space to validate changes in dbt without impacting live data or processes..
Looker Tests
Looker tests are designed to ensure the accuracy and reliability of key performance indicators (KPIs) used in Dashboards. By comparing the KPIs to historical data, any unexpected changes can be detected. This process ensures that both the structure and the results of business metrics remain accurate as the underlying data evolves, safeguarding the integrity of reporting and analytics.
Setting Up a Dedicated Looker development project
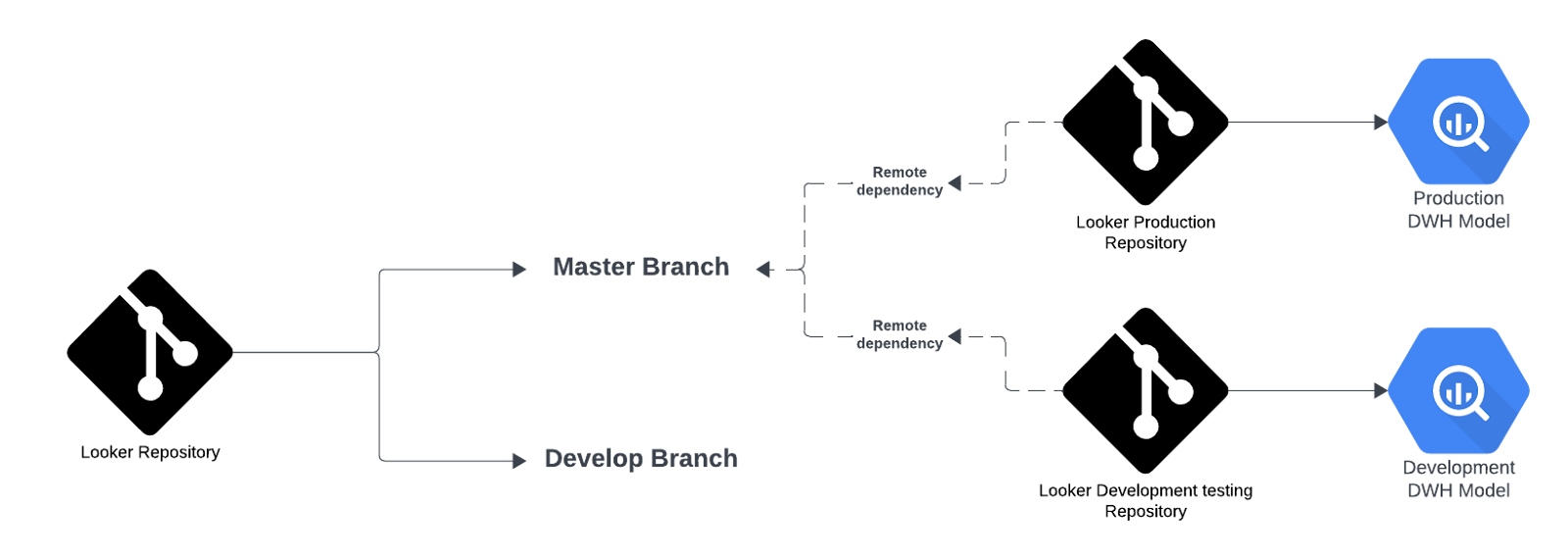
One effective approach is to create a “dev-testing” project within Looker. This project connects to the dbt development data warehouse, using its data specifically for testing purposes. It also has a remote dependency on the master branch of the primary Looker project while maintaining its own git repository.
Here’s how the process works:
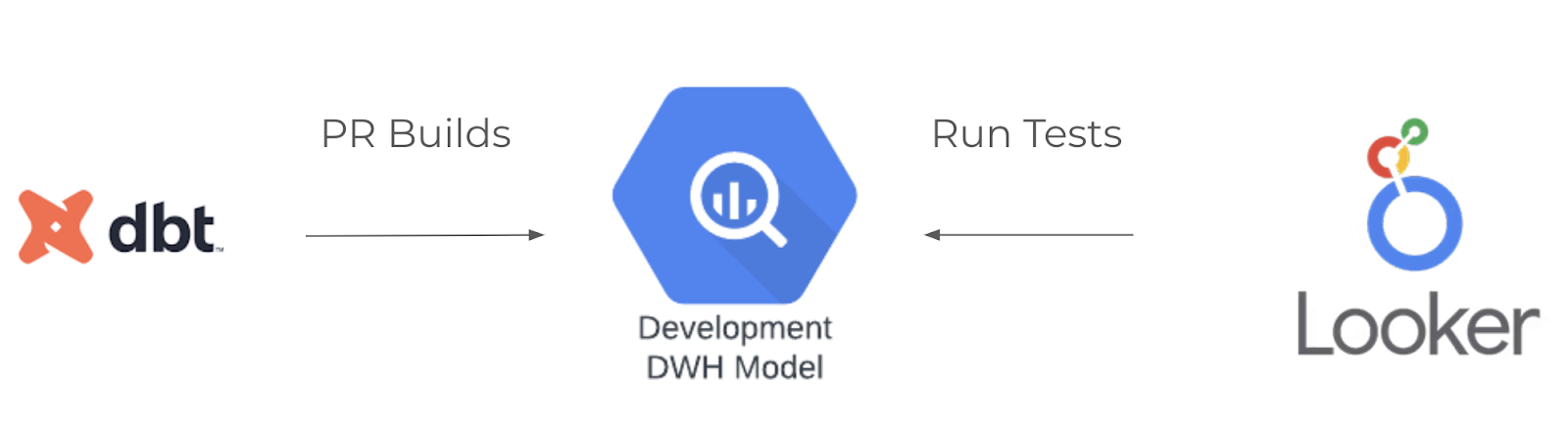
- When a pull request (PR) is created in dbt, triggering a change in data transformations, the development data warehouse is built or updated.
- Once the data warehouse is updated, Looker tests can be executed in the “dev-testing” project using Spectacles, a package that automates looker checks. “Spectacles assert” runs all Looker data tests defined in the project and reports any failures or errors.
By incorporating this setup, you can catch potential errors early in the development cycle, preventing issues from reaching production dashboards. Setting up a CI/CD pipeline to automatically trigger Spectacles after each dbt PR ensures that transformation logic aligns with the business logic represented in Looker.
Optimising Costs for dbt Pull Request Builds
When dbt pull requests trigger the construction of the development data warehouse, costs can escalate rapidly. To control these expenses, you can implement two key optimisations: first, rebuild only the modified tables within the development data warehouse; second, schedule a full rebuild of the entire development data warehouse just once per week. This approach minimises redundant builds, effectively reducing unnecessary costs while maintaining development efficiency.
Testing with Spectacles
Spectacles is a package that automates Looker checks, enabling you to define and streamline tests for Looker models while ensuring data consistency. It supports four key types of automated checks:
- Content Validation
- Identifies content (Dashboards and Looks) that have errors.
- SQL Validation
- Runs queries in the data warehouse to verify the SQL field in each dimension is valid.
- LookML Validator
- Runs Looker’s LookML Validator and returns any syntax issues with your LookML.
- Assert Validator
- Runs any Looker Data Tests that were defined and returns all failures and errors
The Assert Validator is particularly useful for pointing to a development data warehouse and running Looker tests with development data.
Creating Looker Environment Separation
In Looker, creating separate production and development environments with multiple instances can quickly become costly. Instead, we can achieve separation using branch separation within the main Looker repository, avoiding the need for additional Looker instances.
Branch-Based Environment Management
Rather than maintaining two Looker instances, a more cost-effective solution is to use Git branches to manage development and production environments in a single instance.
- Develop Branch: This branch is dedicated to ongoing development work.
- Master Branch: The master branch, which is protected, serves as the production environment.
To link the production environment with Looker, a separate Looker project called “looker-prod ” is created. This project uses the master branch as a remote dependency. This ensures that production dashboards remain isolated from development work.
Automating Deployments with GitHub Workflows
To streamline the deployment process, we can configure automated workflows using GitHub Actions. When changes are merged into the master branch, the workflow triggers a deployment to the Looker production environment by updating the master reference in the Looker production repository. Additionally, if Looker’s Advanced Deployment Mode is enabled, a deploy webhook can be set up in GitHub to automatically push Looker code to production.
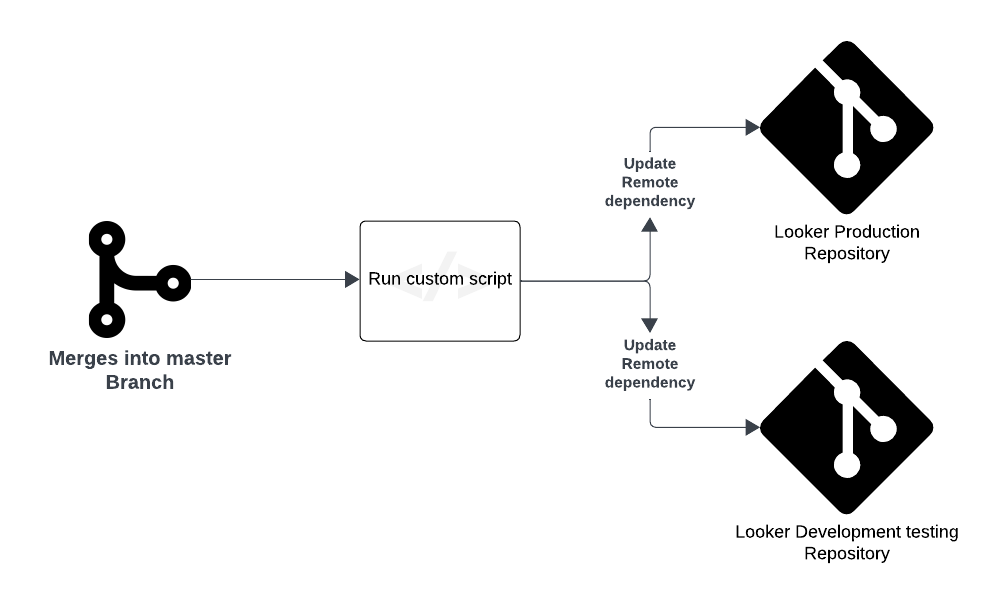
The custom script triggers when a pull request on master is closed. It has two main jobs:
- get_master_latest_commit:
- Checks out the master branch and retrieves the latest commit hash from master.
- update_looker_prodcution_repo:
- Updates the manifest_lock.lkml file with the new commit reference (if it has changed).
- Commits and pushes the update
This automates updating and merging the manifest_lock.lkml with the latest master commit.
Protecting the master branch
Rules to protect the master branch:
- Only accepts merges from the Develop branch
- Force pushes are disabled
- Direct commits are not allowed
- Merge requests with failing GitHub Actions are disallowed
By protecting the master branch and enforcing these rules, you safeguard the stability of the production environment. This setup ensures that only thoroughly tested and validated changes make it to production, while the Develop branch remains flexible for rapid iteration and experimentation.
Conclusion
In this blog post, we explored strategies for ensuring reliable development with dbt and Looker, focusing on creating separate development environments without incurring additional costs. We discussed the importance of using a dedicated development data warehouse, implementing robust testing with Spectacles, and using Git branch separation to manage Looker environments.
By following these practices, your team can:
- Catch errors early, preventing them from affecting production.
- Minimise disruptions to business operations.
- Maintain cost efficiency while improving overall data reliability
If you want to learn more about dbt, read our article “SQL for Data Transformation: From Excel to Expert“. Curious about Looker? Check it’s 4 unknown capabilities!

Are you ready to transform your data development process?
Contact Devoteam today and see how you can implement this streamlined approach in your analytics stack.